The assignment for class 11 is mostly based on the same code as used for class 10. Since I have already explained it in the previous post, I will focus on the additional lines necessary to create frequency/coordinate dictionaries fall all months and days (for years they were already created in the previous assignment).
I had to use the already created generate function to create frequency lists for all days and months instead of only for the years.
To create sequences of months and days between two dates, I used a method learned from Stack Overflow:
#Method for creating yyyy-mm format sequence between 1860-11 and 1865-12:
import datetime as dt
from dateutil.relativedelta import relativedelta
list_months = []
yyyymm_1 = '186011'
yyyymm_2 = '186512'
MONTH = relativedelta(months=+1)
fmt = '%Y%m'
date_1 = dt.datetime.strptime(yyyymm_1, fmt).date()
date_2 = dt.datetime.strptime(yyyymm_2, fmt).date()
d = date_1
while d <= date_2:
print(d.strftime('%Y')+"-"+d.strftime('%m'))
d += MONTH
#The variation of the method for creating yyyy-mm-dd format sequence between 1860-11-01 and 1866-01-01:
import datetime as dt
from dateutil.relativedelta import relativedelta
yyyymm_1 = '186011'
yyyymm_2 = '186601'
DAYS = relativedelta(days=+1)
fmt = '%Y%m'
date_1 = dt.datetime.strptime(yyyymm_1, fmt).date()
date_2 = dt.datetime.strptime(yyyymm_2, fmt).date()
d = date_1
while d <= date_2:
print(d)
d += DAYS
After printing out the yyyy-mm and yyyy-mm-dd sequences in Jupyter Notebook, I copy-pasted them into Sublime Text and using the regular expressions
FIND ALL ^\d REPLACE ALL WITH generate("1 and FIND ALL \n REPLACE ALL WITH ")\n, I obtained sequences of the following format which can be pasted into jupyter notebook:
generate(“1860-11”)
[…]
generate(“1865-12”);
generate(“1860-11-01”)
[…]
generate(“1865-12-01”)
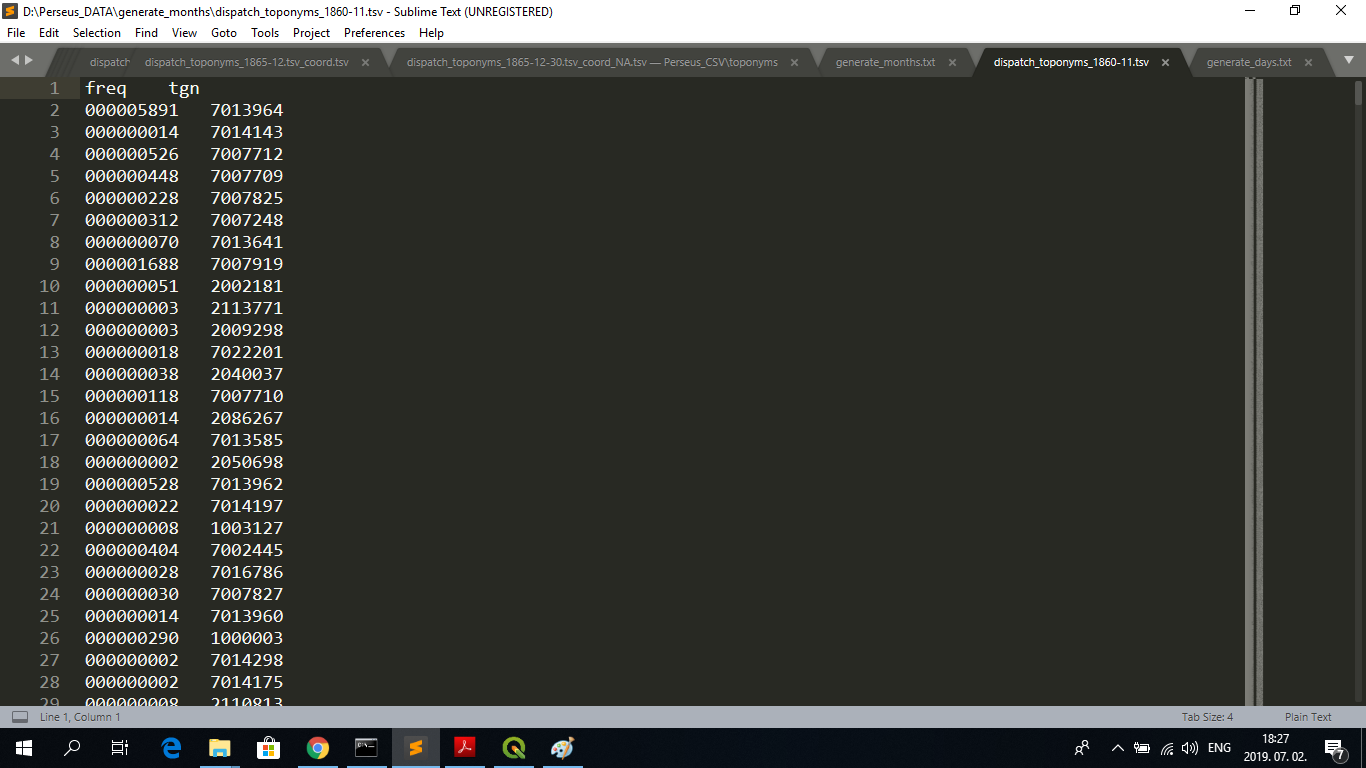
The results look like this:
This is followed by applying the match function to all the generated files (based on months/days):
import os
target2 = "path_to_files"
lof2 = os.listdir(target2)
dictionary = loadTGN(target+"tgn_data_light.tsv")
for file in lof2:
match(file, dictionary)