For this assignment I initially used the first version of the code provided for class 11 as an aid, and successfully created the “frequency » city, state/country name » tgn ID” formatted CSV file.
The code starts with importing the necessary Python libraries, setting the source and target folders and creating the topoDict dictionary:
import re, os
source = "C:\\Users\\Siming\\Desktop\\siming\\AC_studies\\Tools and Techniques for Digital Humanities\\Perseus\\Perseus_XML\\"
target = "C:\\Users\\Siming\\Desktop\\siming\\AC_studies\\Tools and Techniques for Digital Humanities\\Class10_Text_to_map\\homework\\"
topoDict = {}
It goes on by defining the function updateDic to count frequencies and collectTaggedToponyms to extract place names from the XML files:
def updateDic(dic, key):
if key in dic:
dic[key] += 1
else:
dic[key] = 1
def collectTaggedToponyms(xmlText, dic):
xmlText = re.sub("\s+", " ", xmlText)
#date = re.search(r'<date value="([\d-]+)"', xmlText).group(1) (This was not necessary for this assignment)
count1, count2 = 0,0
for t in re.findall(r"<placeName[^<]+</placeName>", xmlText):
t = t.lower()
if 'tgn,' in t:
if re.search(r'reg="([^"]+)"', t):
reg = re.search(r'reg="([^"]+)"', t).group(1)
else:
#print(t)
reg = 0
if re.search(r'key="([^"]+)"', t):
key = re.search(r'key="([^"]+)"', t).group(1)
else:
#print(t)
key = 0
if reg == 0 or key == 0:
count1 += 1
else:
count2 += 1
keyNew = reg+"\t"+key
updateDic(topoDict, keyNew)
## if count1 >= 0:
## print("%s: %d out of %d toponyms misstagged." % (date, count1, count2))
Finally, the function collectRawToponyms is defined to create the frequency list and sets the threshold for adding items to the list at min. 100 appearances:
def collectRawToponyms(source):
lof = os.listdir(source)
lof = sorted(lof, reverse=False)
counter = 0
for f in lof:
if f.startswith("dltext"): # fileName test
with open(source + f, "r", encoding="utf8") as f1:
text = f1.read()
collectTaggedToponyms(text, topoDict)
freqList = []
thresh = 100
for k,v in topoDict.items():
if v >= thresh:
freqList.append("%09d\t%s" % (v,k))
print("Number of unique items with freq at least %d: %d" % (thresh, len(freqList)))
# Number of unique items with freq at least 1: 9246
# Number of unique items with freq at least 2: 5388
# Number of unique items with freq at least 3: 4062
# Number of unique items with freq at least 4: 3344
# Number of unique items with freq at least 5: 2932
freqList = "\n".join(sorted(freqList, reverse=True))
with open(target + "freqList.csv", "w", encoding="utf8") as f9:
f9.write(freqList)
collectRawToponyms(source)
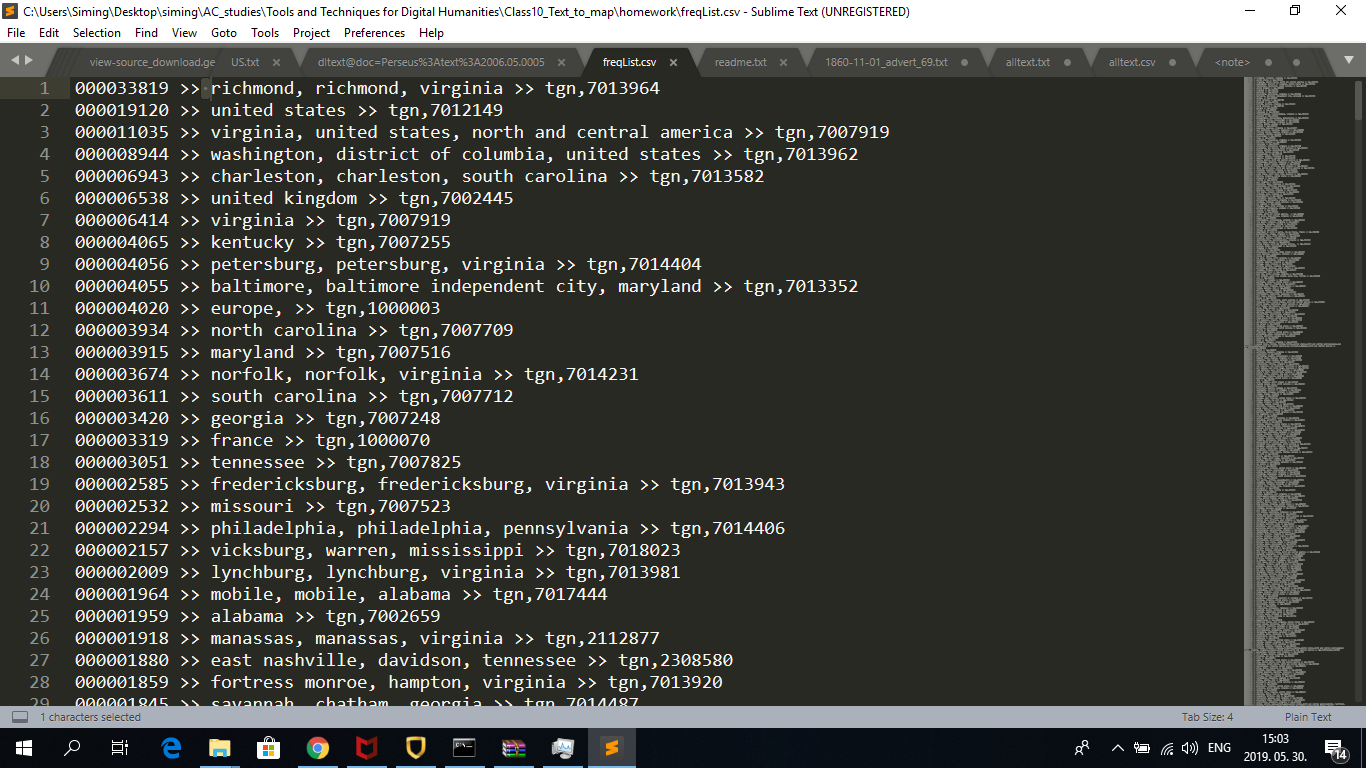
So far everything was clear, and the frequency list was successfully created. The abbreviation ‘tgn’ stands for the ‘Getty’ Thesaurus of Geographic Names ID of the given location as I figured out. I substituted “\t” for “ » “ for easier readability. The result looks like this:
Meanwhile, a new version of the solution was published on the website which made it easier to use the data for the next assignment as well. After the usual steps, a generate function is defined in order to separate the units (articles, advertizements, etc.) by the year of publication. Separate TSV files for each five years are created, which combine frequencies with locations (tgn IDs) in the given year:
import re, os
source = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_XML_ORIGINAL\\"
target = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_CSV\\"
lof = os.listdir(source)
counter = 0 # general counter to keep track of the progress
def generate(filter):
topCountDictionary = {}
print(filter)
counter = 0
for f in lof:
if f.startswith("dltext"): # fileName test
with open(source + f, "r", encoding="utf8") as f1:
text = f1.read()
text = text.replace("&", "&")
# try to find the date
date = re.search(r'<date value="([\d-]+)"', text).group(1)
#print(date)
if date.startswith(filter):
for tg in re.findall(r"(tgn,\d+)", text):
tgn = tg.split(",")[1]
if tgn in topCountDictionary:
topCountDictionary[tgn] += 1
else:
topCountDictionary[tgn] = 1
#input(topCountDictionary)
top_TSV = []
for k,v in topCountDictionary.items():
val = "%09d\t%s" % (v, k)
#input(val)
top_TSV.append(val)
# saving
header = "freq\ttgn\n"
with open(target+"dispatch_toponyms_%s.tsv" % filter, "w", encoding="utf8") as f9:
f9.write(header+"\n".join(top_TSV))
#print(counter)
#generate("186")
generate("1861")
generate("1862")
generate("1863")
generate("1864")
generate("1865")
#I also generated the TSV file for December 1865 and December 30th, 1865, to demonstrate that the code works for months and days as well.
generate("1865-12")
generate("1865-12-30")
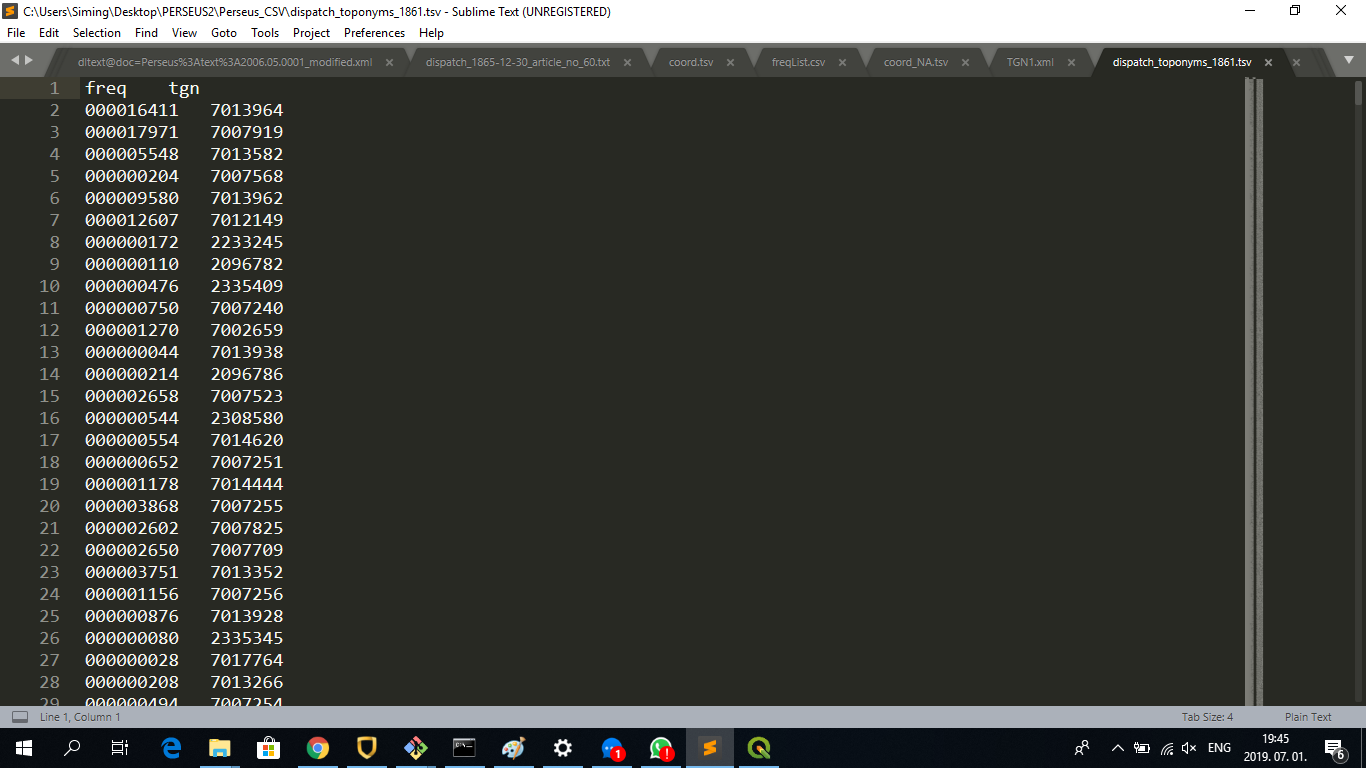
The resulting files look like this:
Following this, the TGN data has to be generated in order to match it with the frequency lists. The TGN data (XML format) is downloaded from the Getty Vocabularies Download Center into the source folder. The data is read and split along the </Subject> final tag. Place IDs, place names, latitudes and longitudes are extracted using regular expressions and they are added to tgnList. If latitude and longitude is not available, the string “NA” (not available) is added and the entries are added to a separate list called tgnListNA:
import re, os
source = "C:\\Users\\Siming\\Desktop\\siming\\AC_studies\\Tools and Techniques for Digital Humanities\\Class10_Text_to_map\\tgn\\"
target = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_CSV\\"
def generateTGNdata(source):
lof = os.listdir(source)
tgnList = []
tgnListNA = []
count = 0
for f in lof:
if f.startswith("TGN"): # fileName test
print(f)
with open(source+f, "r", encoding="utf8") as f1:
data = f1.read()
data = re.split("</Subject>", data)
for d in data:
d = re.sub("\n +", "", d)
#print(d)
if "Subject_ID" in d:
# SUBJECT ID
placeID = re.search(r"Subject_ID=\"(\d+)\"", d).group(1)
#print(placeID)
# NAME OF THE PLACE
placeName = re.search(r"<Term_Text>([^<]+)</Term_Text>", d).group(1)
#print(placeName)
# COORDINATES
if "<Coordinates>" in d:
latGr = re.search(r"<Latitude>(.*)</Latitude>", d).group(1)
lat = re.search(r"<Decimal>(.*)</Decimal>", latGr).group(1)
lonGr = re.search(r"<Longitude>(.*)</Longitude>", d).group(1)
lon = re.search(r"<Decimal>(.*)</Decimal>", lonGr).group(1)
#print(lat)
#print(lon)
else:
lat = "NA"
lon = "NA"
tgnList.append("\t".join([placeID, placeName, lat, lon]))
#input(tgnList)
if lat == "NA":
print("\t"+ "; ".join([placeID, placeName, lat, lon]))
tgnListNA.append("\t".join([placeID, placeName, lat, lon]))
Two TSV files (tgn_data_light.tsv, tgn_data_light_NA.tsv) are created based on the tgnList and tgnListNA, both with the header tgnID\tplacename\tlat\tlon\n:
# saving
header = "tgnID\tplacename\tlat\tlon\n"
with open(target+"tgn_data_light.tsv", "w", encoding="utf8") as f9a:
f9a.write(header+"\n".join(tgnList))
with open(target+"tgn_data_light_NA.tsv", "w", encoding="utf8") as f9b:
f9b.write(header+"\n".join(tgnListNA))
print("TGN has %d items" % len(tgnList))
generateTGNdata(source)
#TGN has 2,487,572 items
# 17,613 items do not have coordinates.
In the next step, loadTGN is defined to load the TGN data into a dictionary:
import re, os
def loadTGN(tgnTSV):
with open(tgnTSV, "r", encoding="utf8") as f1:
data = f1.read().split("\n")
dic = {}
for d in data:
d = d.split("\t")
dic[d[0]] = d
return(dic)
After this, match is defined for matching frequencies of the Dispatch locations with the TGN dictionary. The code starts with opening the frequency list TSV file, splitting it by \t (starting from the second row to exclude the header) and naming the second column tgnID. If tgnID from the frequency list can be found in the TGN dictionary, the ID is joined with the frequency in a variable named val. If “NA” appears in val (meaning that the coordinates are not available, see above), val is appended to the list for entries without coordinates, named dataNewNA. Else, val is appended to the list dataNew:
target = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_CSV\\"
def match(freqFile, dicToMatch):
with open(freqFile, "r", encoding="utf8") as f1:
data = f1.read().split("\n")
dataNew = []
dataNewNA = []
count = 0
for d in data[1:]:
tgnID = d.split("\t")[1]
freq = d.split("\t")[0]
if tgnID in dicToMatch:
val = "\t".join(dicToMatch[tgnID])
val = val + "\t" + freq
if "\tNA\t" in val:
dataNewNA.append(val)
else:
dataNew.append(val)
else:
print("%s (%d) not in TGN!" % (tgnID, int(freq)))
count += 1
The matched TSV files are created by adding _coord.tsv and _coord_NA.tsv (for entries without coordinates) to the original filename. All the new TSV files will include the header tgnID\tplacename\tlat\tlon\tfreq\n:
header = "tgnID\tplacename\tlat\tlon\tfreq\n"
with open(freqFile+"_coord.tsv", "w", encoding="utf8") as f9a:
f9a.write(header + "\n".join(dataNew))
with open(freqFile+"_coord_NA.tsv", "w", encoding="utf8") as f9b:
f9b.write(header + "\n".join(dataNewNA))
print("%d item have not been matched..." % count)
The loadTGN and match functions are applied in the following way:
target = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_CSV\\"
dictionary = loadTGN(target+"tgn_data_light.tsv")
match(target+"dispatch_toponyms_1861.tsv", dictionary)
match(target+"dispatch_toponyms_1862.tsv", dictionary)
match(target+"dispatch_toponyms_1863.tsv", dictionary)
match(target+"dispatch_toponyms_1864.tsv", dictionary)
match(target+"dispatch_toponyms_1865.tsv", dictionary)
match(target+"dispatch_toponyms_1865-12.tsv", dictionary)
match(target+"dispatch_toponyms_1865-12-30.tsv", dictionary)
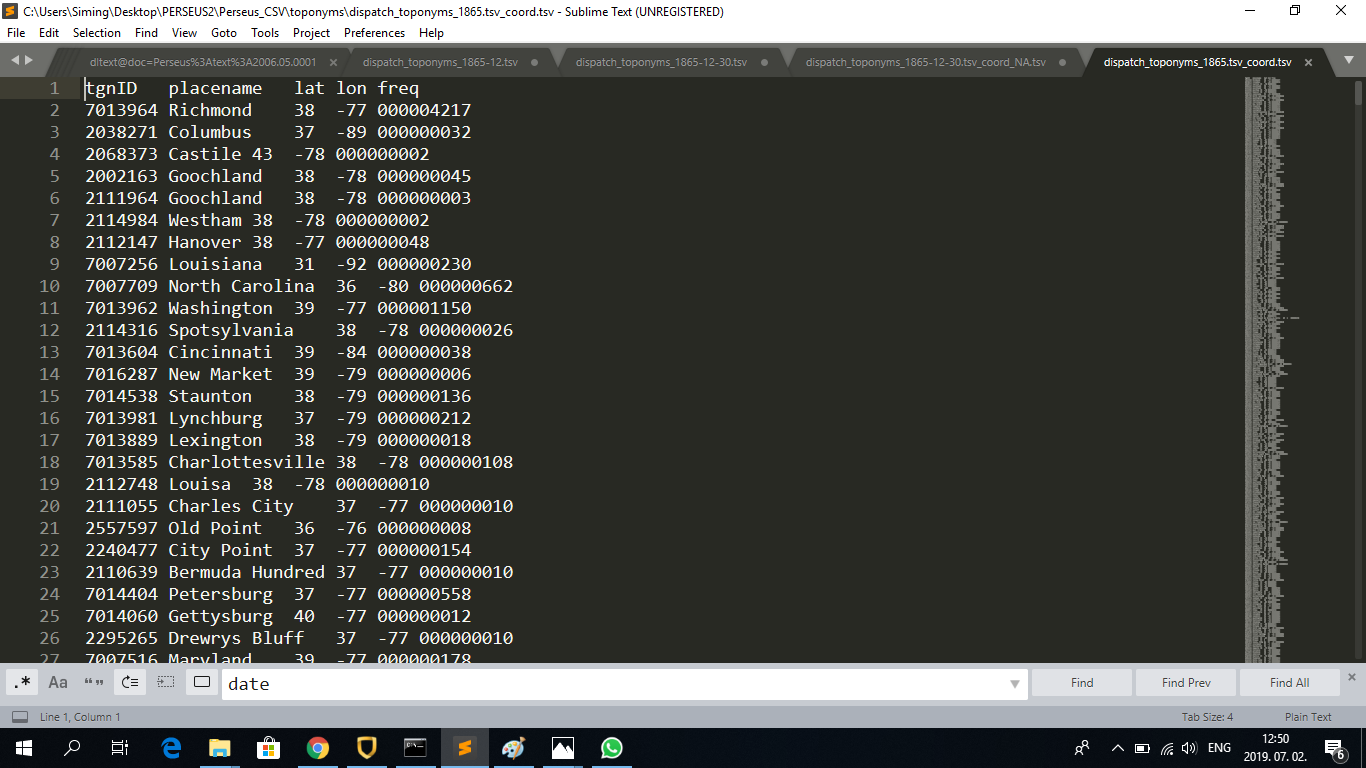
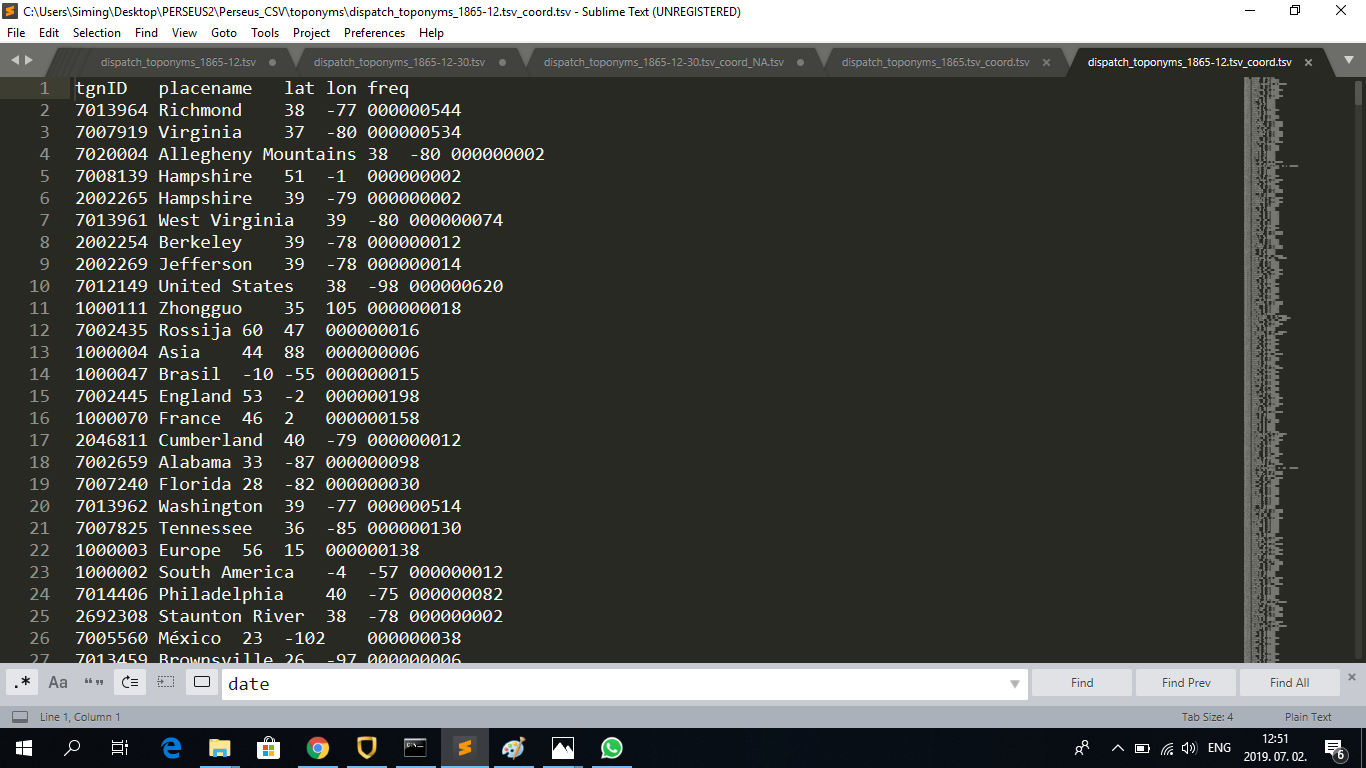
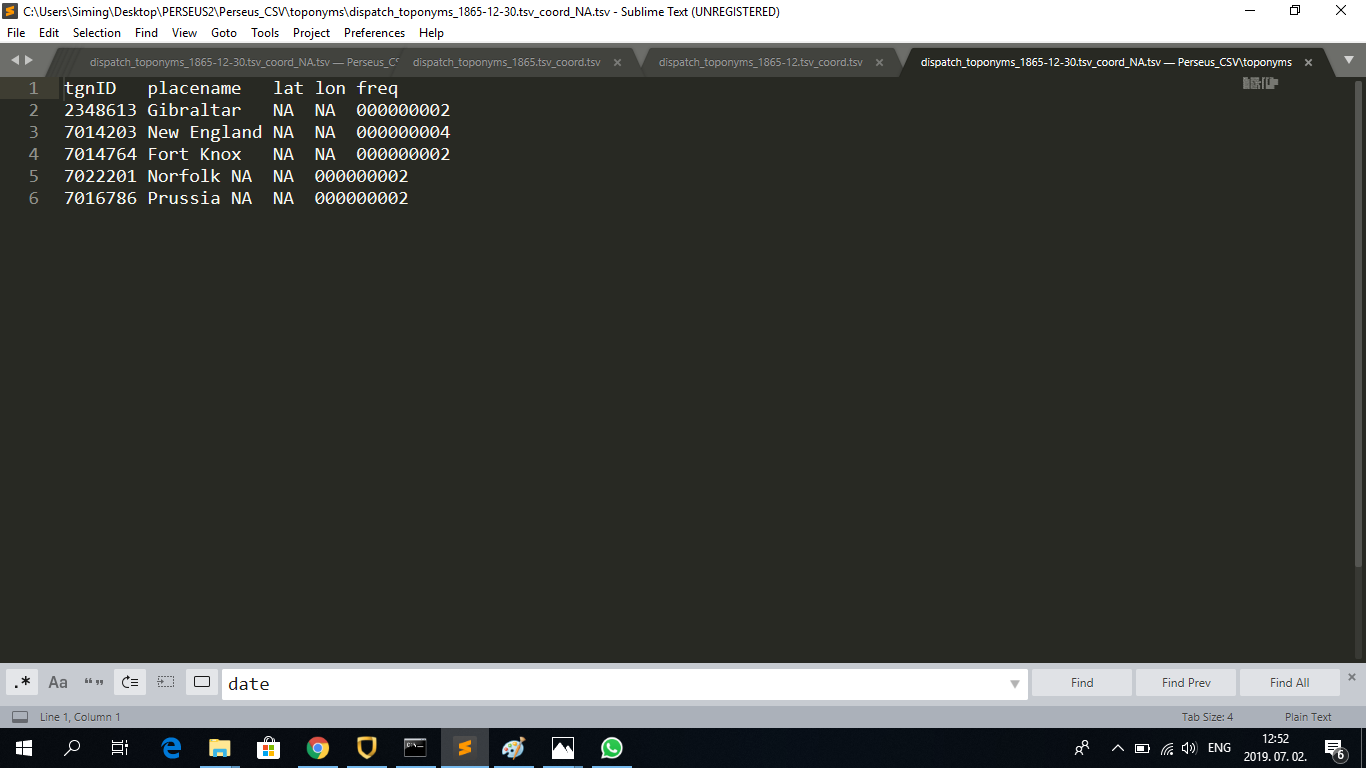
The resulting TSV files look like this (examples of the 1865, 1865-12 and 1865-12-30/NA TSV file):
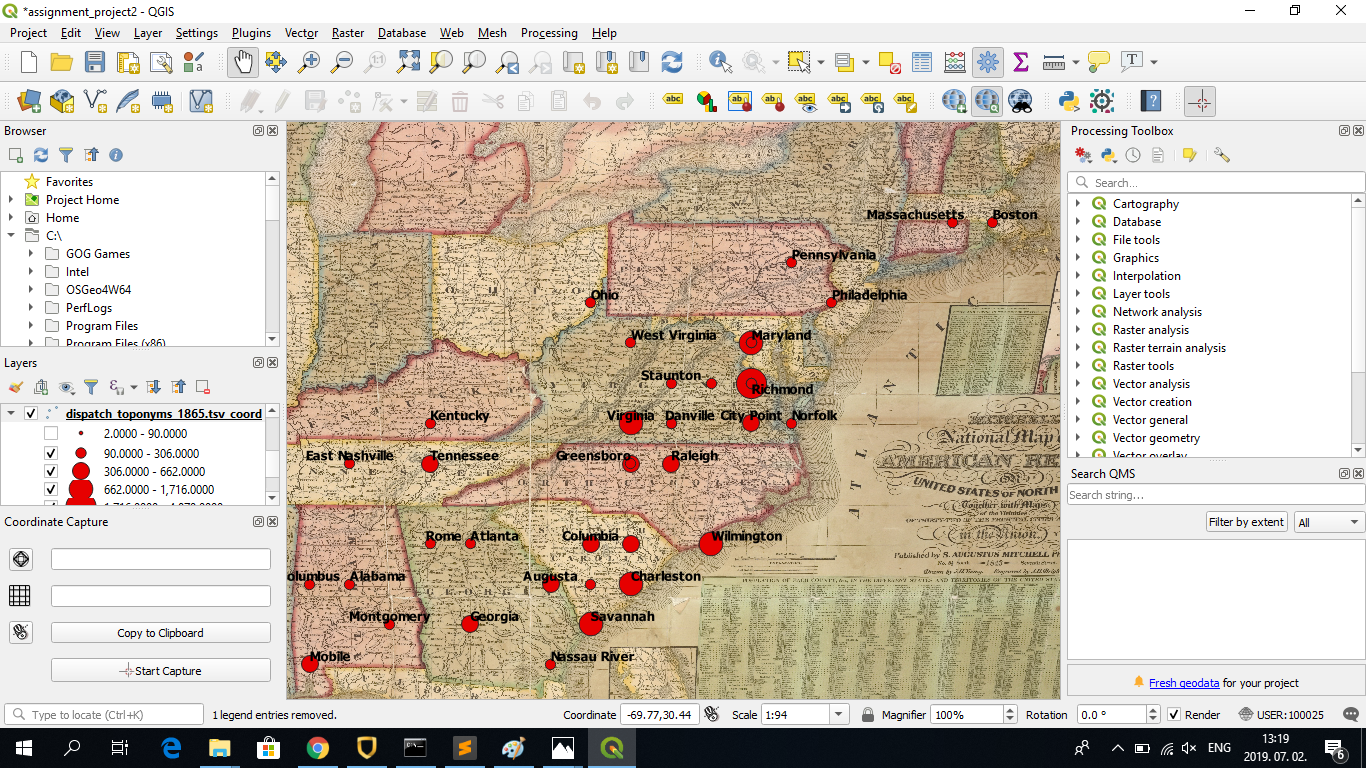
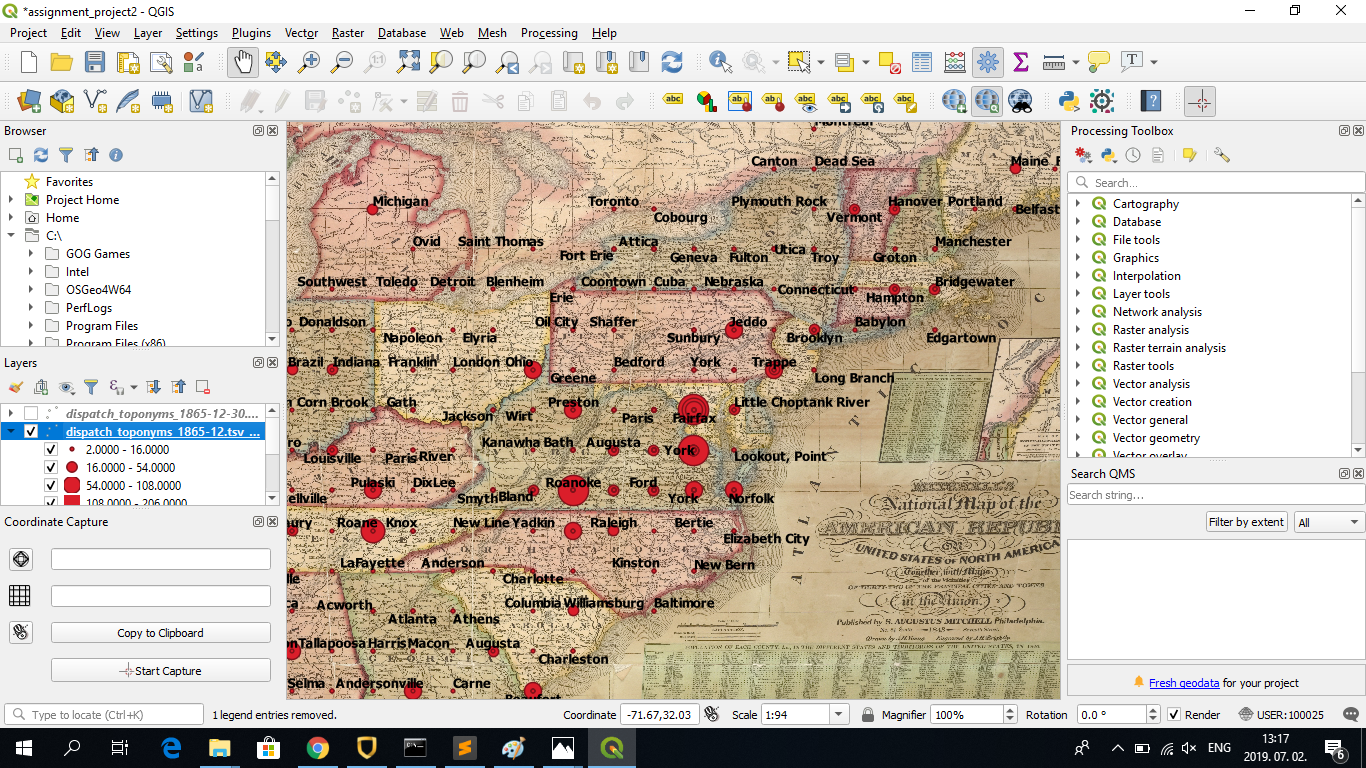
Following this, I opened QGIS, added the raster layer we used for the Georeferencing assignment (1843 US map), clicked on ‘Add Delimited Text Layer’ and added the three _coord.tsv files on 1865, 1865-12 and 1865-12-30. I followed the instructions on this website to create proportional symbology (set the frequency column of the TSV files as the basis for the sizes of the points):