I tried using the following method: First collecting all the articles into one text file and removing the #ID tag and data, the other #… tags, and substituting those tags with tabs. Then I split the new text file into elements along the tabs. However, I did not manage to write the items of the list onto a single line by every fourth element in order to create the TSV file.
import re, os
source = "C:\\Users\\Siming\\Desktop\\siming\\AC_studies\\Tools and Techniques for Digital Humanities\\Perseus\\Perseus_articles\\"
target = "C:\\Users\\Siming\\Desktop\\siming\\AC_studies\\Tools and Techniques for Digital Humanities\\Perseus\\Perseus_articles_data\\"
lof = os.listdir(source)
with open(target+'alltext.txt', 'w', encoding="utf8") as outfile:
for fname in lof:
with open(source+fname, 'r', encoding="utf8") as infile:
outfile.write(infile.read())
#Remove: "#.+?:\s"
#Replace /#[A-Z]+:\s/ with \t
with open(target+'alltext.txt', 'r', encoding="utf8") as f1:
text = f1.read()
text = re.sub("#ID:.+[^#]","", text)
text = re.sub("#.+?:\s","\t",text)
with open(target+'alltext_mod.txt', 'w', encoding="utf8") as f2:
f2.write(text)
with open(target+'alltext_mod.txt', 'r', encoding="utf8") as f3:
split = f3.read()
split = re.split("\t", split)
After trying the solution provided on the TNT website in Jupyter Notebook, it worked fine for me. The code starts with importing the necessary libraries, setting the source/target folders, listing the files in source and creating the counter and the OurCSV list:
import re, os
source = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_XML_ORIGINAL\\"
target = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_TSV\\"
lof = os.listdir(source)
counter = 0 # general counter to keep track of the progress
ourCSV = []
This is followed by creating a loop for lof in which we use regular expressions to search for date and split the issues into units (including all types of units such as advertizements and not only articles as in the previous class). A counter is created for counting the number of units:
for f in lof:
if f.startswith("dltext"): # fileName test
with open(source + f, "r", encoding="utf8") as f1:
text = f1.read()
# try to find the date
date = re.search(r'<date value="([\d-]+)"', text).group(1)
# splitting the issue into articles/items
split = re.split("<div3 ", text)
c = 0 # item counter
for s in split[1:]:
c += 1
s = "<div3 " + s # a step to restore the integrity of items
#input(s)
The next steps include using the try-except method to extract the types and headers of the units, including the information whether the unit has a type and header. The XML tags are removed from the text and “;;;” is placed at the end of each line. The values are delimited by TAB (hence the name TSV). The counter is defined at the end of the loop to count every 100 units:
# try to find a unitType
try:
unitType = re.search(r'type="([^\"]+)"', s).group(1)
except:
unitType = "noType"
print(s)
# try to find a header
try:
header = re.search(r'<head>(.*)</head>', s).group(1)
header = re.sub("<[^<]+>", "", header)
except:
header = "NO HEADER"
#print("No header found!")
text = re.sub("<[^<]+>", "", s)
text = re.sub(" +\n|\n +", "\n", text)
text = re.sub("\n+", ";;; ", text)
# generating necessary bits
fName = date+"_"+unitType+"_"+str(c)
itemID = date+"_"+unitType+"_"+str(c)
dateVar = date
#unitType = unitType
#header = header
text = text.replace("\t", " ")
# creating a text variable
var = "\t".join([itemID,dateVar,unitType,header,text])
#input(var)
ourCSV.append(var)
# count processed issues and print progress counter at every 100
counter += 1
if counter % 100 == 0:
print(counter)
Finally, all this is written to CSV file in the target folder:
# saving
with open(target+"dispatch_as_TSV.csv", "w", encoding="utf8") as f9:
f9.write("\n".join(ourCSV))
print(counter)
The result looks like this:
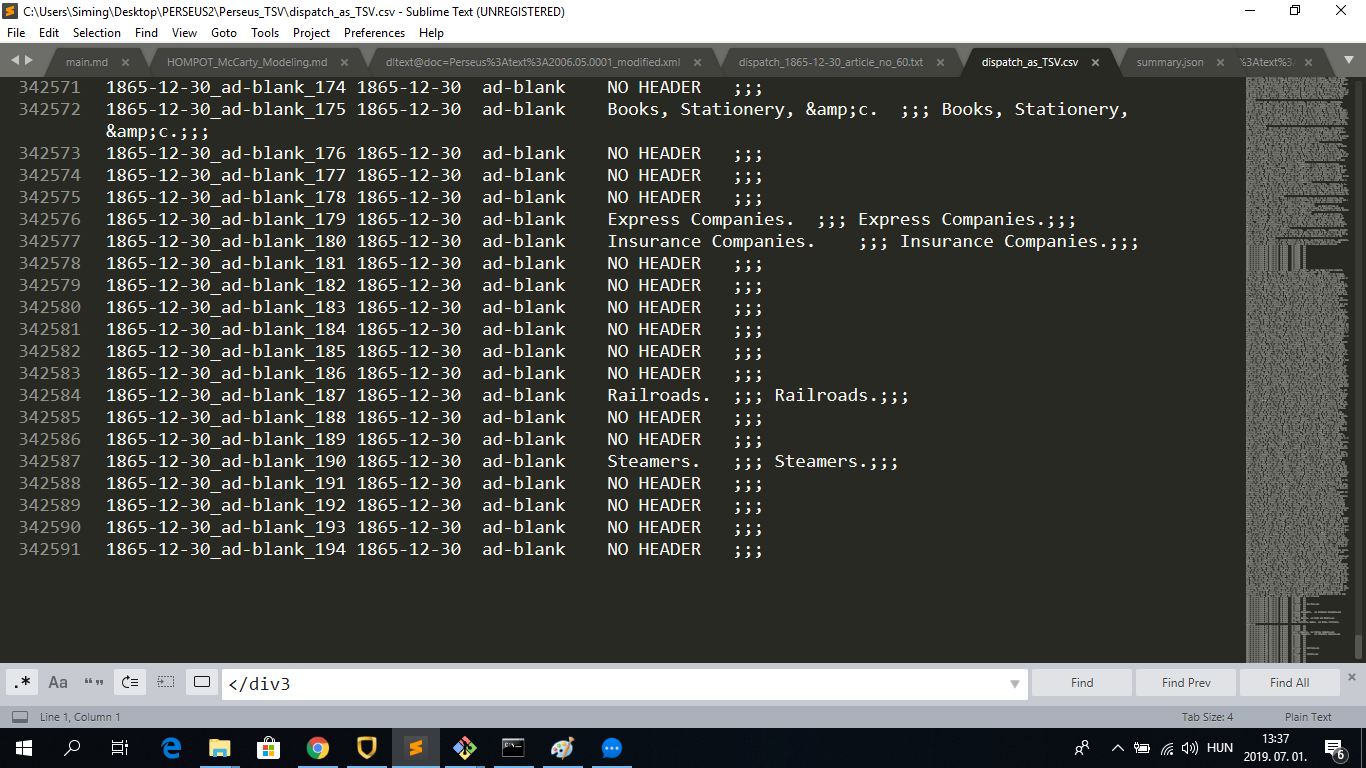
While the required CSV file was generated successfully, I would point out that Jupyter Notebook only counted 1349 units despite the 342,591 lines of the CSV file: