1/A. Creating the cleaned copies of the Perseus XML files
For creating the cleaned copies of the Perseus XML files, I took the following steps:
-
Importing the RegEx module into Python:
import re. -
To make things easier, defining the path of the folder used for this excercise:
folder_path = 'C:\\Users\\Siming\\Desktop\\siming\\AC_studies\\Tools and Techniques for Digital Humanities\\Perseus\\Perseus_XML\\'. - Importing the OS (Operation System) module and listing files in the folder with the ‘listdir’ function, followed by printing the full paths of the files to check the results:
import os lof = os.listdir(folder_path) for file in lof: print(folder_path+file) - I created a loop for opening and reading each file of the list, saved the results in data2, used the re.sub function,
created a new dataset after removing the XML tags, named the new files by adding “_modified.xml” to the original filename
and wrote the new files:
for file in lof: with open(folder_path+file, "r", encoding="utf8") as f2: data2 = f2.read() dataNew2 = re.sub("<[^<]+>", "", data2) newFN = file + "_modified.xml" with open(newFN, "w", encoding="utf8") as f3: f3.write(dataNew2)
I could not, however, figure out how to set the target folder for the new files, therefore it was by default saved into my
Documents folder. Using ‘date of creation’ based listing, I selected the new files manually and moved them into a new folder
created for this assignment.
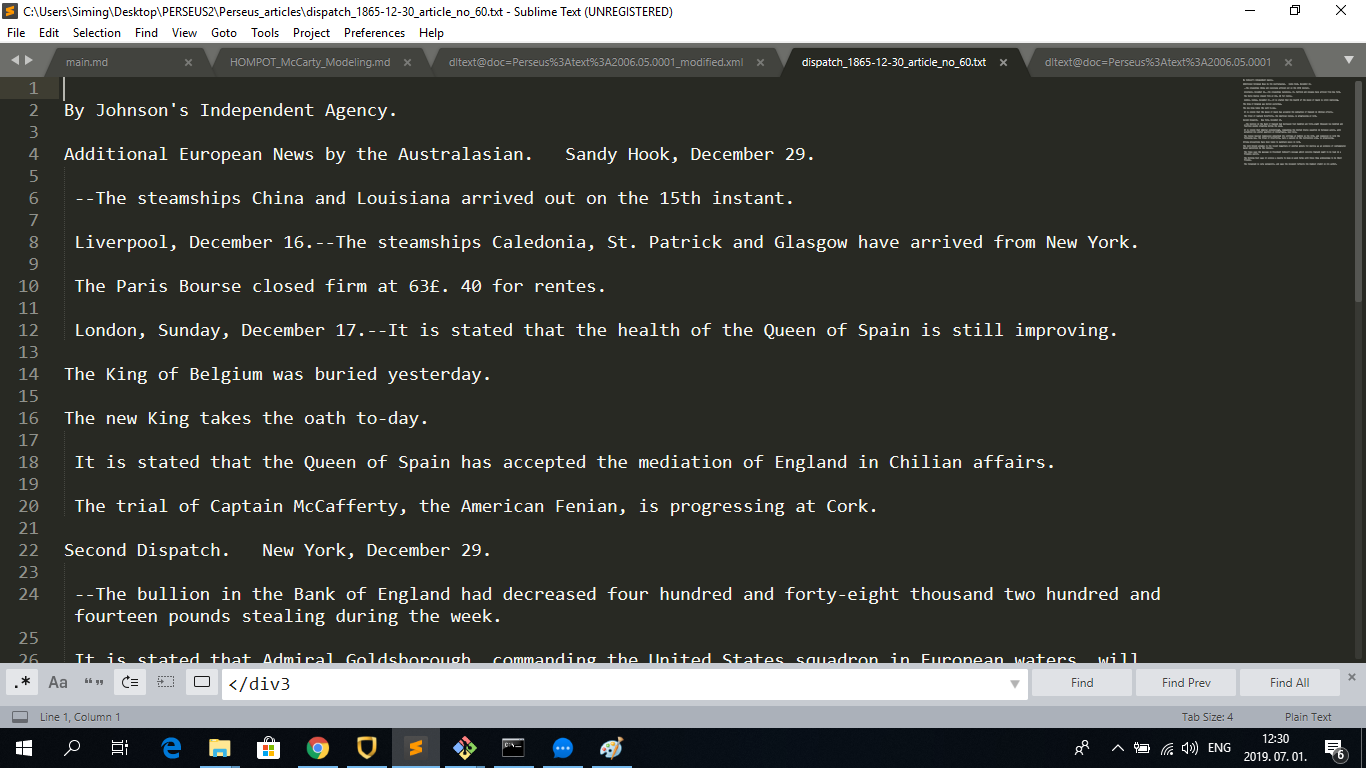
The cleaned articles look like this:
1/B. Splitting issues into articles
I figured out that the publication date is included in each issue after the tag
with open(folder_path+file, "r", encoding="utf8") as f2:
data2 = f2.read()
issue_dates = re.search(r"</pubPlace> <date value=\"(.*)\" authname", data2).group(1)
print(issue_dates)
Regarding the splitting of the issues into articles, the tag
with open(folder_path+"dltext@doc=Perseus%3Atext%3A2006.05.0001", "r", encoding="utf8") as text_split1:
data_split1 = text_split1.read()
results_split1 = re.split("</div3>", data_split1)
After consulting the solution provided on the TNT website I tried to apply it but it only produced the files until 1861-02-23_notice_102.txt, files from articles dated later than 1861-02-23 were not created (the target directory included only 21,982 resulting files). I checked out the solutions of some of the other students in the comments section of the website and found Daniel’s approach approach with BeautifulSoup especially useful. The following code worked well for me, producing all the required files until 1865-12-30 (altogether 69,506 files in the target directory) and it was easy to follow its logic. The html.parser function of BeautifulSoup which is apparently able to parse XML files as well makes it easier to find_all the necessary tags and get their value. Following this, Regex can be used to remove the XML tags, similarly to the first excercise.
from bs4 import BeautifulSoup
import re
import os
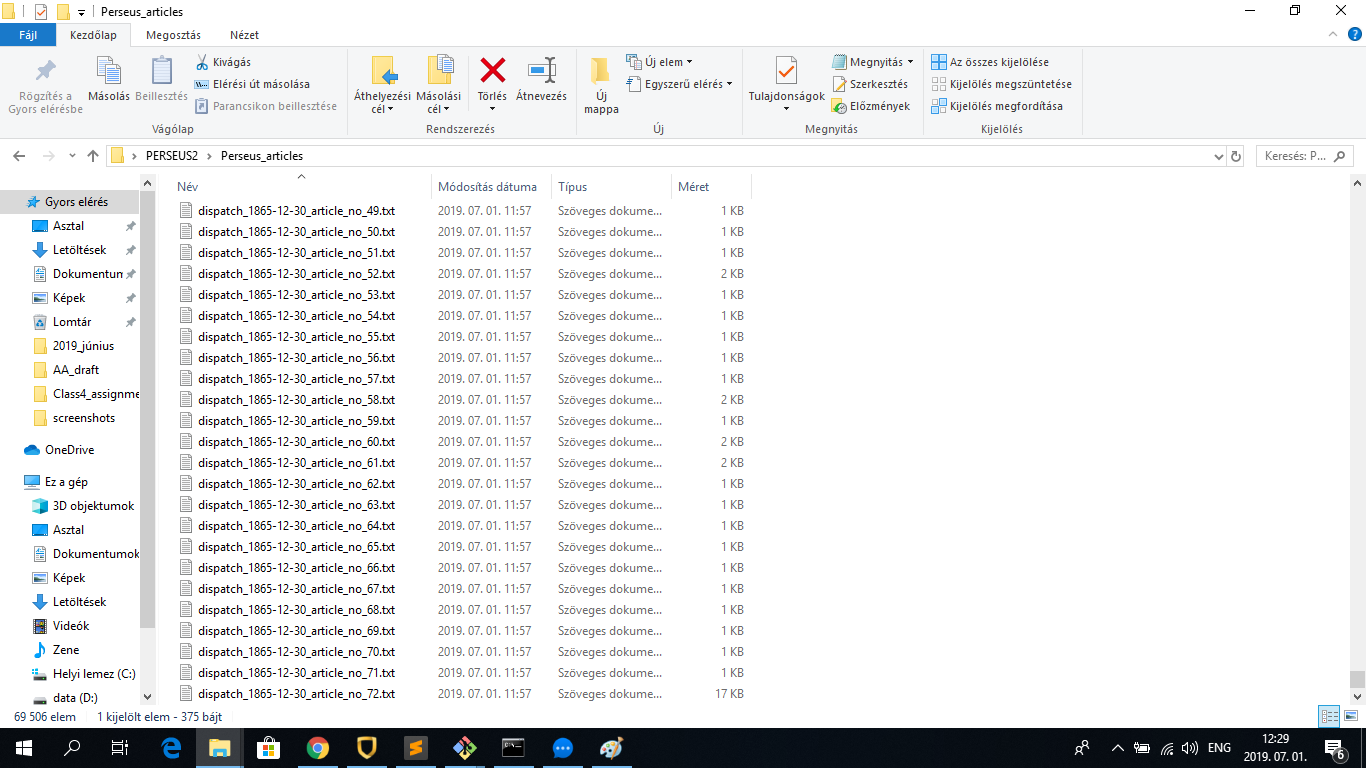
newPathToFolder = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_articles\\"
pathToFolder = "C:\\Users\\Siming\\Desktop\\PERSEUS2\\Perseus_XML_ORIGINAL\\"
listOfFiles = os.listdir(pathToFolder)
# for loop that opens all files of a defined folder and stores it with BeautifulSoup in variable soup
for f in listOfFiles:
soup = BeautifulSoup (open(pathToFolder+f, "r", encoding="utf8"), features="html.parser")
issue_date = soup.find_all("date", limit=2)[1] # only returns the second match
issue_date = issue_date.get("value")
# searches for all tags with "div3" and stores it in variable "articles"
articles = soup.find_all("div3", {"type":"article"})
# for loop to count each articles with "a"
# automatically seperates all articles in "item"
for a, item in enumerate(articles[1:]): # with the latest part after articles the counter starts at 1 instead of 0
# assiging the counter to a variable
counter = a
# cleaning all articles of xml tags
article = re.sub("<[^<]+>", "", str(item))
# creates a new file in a target folder with name + article counter + name + issue_date + txt file
newfile = newPathToFolder + "dispatch_" + str(issue_date) + "_article_no_" + str(counter) + ".txt"
# opens the newfile and writes each article into a sperate file
with open(newfile, "w", encoding="utf8") as f9:
f9.write(article)
The results look like this: